Loading...
Project
Technical University Dortmund (TUDo)
Parallel Scalable Multilevel Methods
The existing
(geometric) multigrid solvers in FEATFLOW should be extended, particularly with respect to
hardware-oriented smoothers that can better utilize the aforementioned range of accelerator
hardware, and multilevel coarse-grid solvers, and realized on the corresponding computing
platforms. Furthermore, new techniques of prehandling in conjunction with special Schur complement
methods [83] for the pressure-Poisson problems occurring in FEATFLOW are to be integrated. These
methods make it possible to compute in low precision without loss of accuracy, thereby especially
leveraging the high performance of accelerator hardware. In particular, in conjunction with
time-simultaneous or time-parallel approaches [15], this allows for custom solvers for many time
steps that can primarily utilize NVIDIA's Tensor Core architectures. For variants of this new
solution approach, significant accelerations of more than a factor of 100 have already been
demonstrated on NVIDIA V100 or A100 architectures compared to the already highly optimized
multigrid solvers in FEAT3 [83]. Further variants that can utilize the high performance of dense
matrix-matrix applications on Tensor Core architectures in reduced precision (single or even half
precision) primarily for 3D configurations are currently being realized and will be integrated into
FEATFLOW in the near future. The further development of methodical components regarding
discretization and solvers, and their realization within FEATFLOW or FEAT3 is part of current DFG
and AIF projects, although the software-technical extension of the FEATFLOW software and Exascale
computers are not the primary focus as target architectures.
Project Gallery
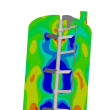


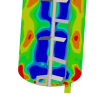


© StroemungsRaum Team, All Right Reserved.
Template designed by HTML Codex
Template distributed by: ThemeWagon
Template designed by HTML Codex
Template distributed by: ThemeWagon